
To work with any system, the first thing you need to grasp is the basic concepts used with that system. So, in this tutorial, I would like to explain the important concepts in Kubernetes to you guys!
These concepts include:
Table of Contents
Node
A node is a machine that can be a hardware machine or a virtual machine. For data centers, the node here will be the hardware machine but for cloud service providers like Google Cloud Platform, the node here is the virtual machine.
These nodes will be organized into clusters, have the services necessary to run the pods, managed by these clusters and used as needed. Any node can be replaced by other nodes in the same cluster.
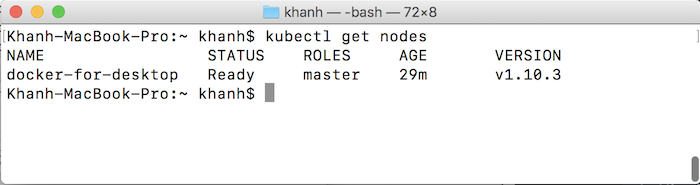
To check the current nodes in the Kubernetes cluster, enter the following command:
|
1 |
kubectl get nodes |
Cluster
As I said, cluster is a system composed of many different nodes. Cluster will handle the management of these nodes.
When an application is deployed to a cluster, this cluster will manage which node our application will be deployed to. If the node that is deploying our application has a problem, the cluster will be responsible for ensuring that our application can work normally, using another node such as …
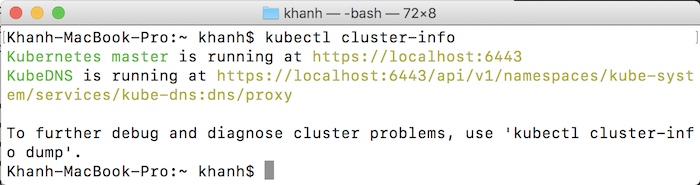
To check cluster information in Kubernetes, you can use the following statement:
|
1 |
kubectl cluster-info |
Persistent Volumes
One problem we usually have is: because the cluster deploys our application to the nodes and manages those nodes and if the cluster is deploying the application having problem, it will automatically deploy our application using other nodes. In case our application has data storage, if it is deployed to another node, it will lose its previous data. To solve this problem, an application data storage location for each node is needed, so that when our node has a problem, the application’s data is still there.
The concept of persistent volumes is proposed to solve this problem. These are the hard disks that can mount to the cluster as persistent volumes as data storage for the application.
Container
If you already know Docker, you will understand this concept so I will not say much about it.
Linux containers are often used to deploy applications.
A container we can deploy many applications but most recommend is still each container for each application.
Pod
The pod is a concept used to refer to a container or some containers that running on Kubernetes. If there are some containers, they have to use the same resource and network to easily communicate with each other.
One pod can be replicated in several copies in Kubernetes. This will make our application run smoothly when there are too many external requests, a pod cannot handle all.
You can view all pods contained in the Kubernetes system using the following command:
|
1 |
kubectl get pods |

Deployment
Pods will not be run directly in Kubernetes, but through a component called Deployment. This ensures that we can replace pods with predefined numbers.
When a Deployment is added, it will initialize a number of pods that we need and manage them.
Ingress
Once our application is deployed to containers managed by the Kubernetes cluster, how do we get access to it? We need to create a channel for external access. This channel is called as Ingress in Kubernetes.
We have several ways to add an Ingress to a cluster, such as using an Ingress Controller or a Load Balancer.
