
Debezium là một công cụ mã nguồn mở distributed platform được sử dụng để capture tất cả các thay đổi liên quan đến database. Bất cứ những thay đổi nào liên quan đến việc insert, update, delete data trong database table, Debezium sẽ capture lại và các bạn có thể sử dụng thông tin này để làm bất cứ điều gì mà các bạn muốn. Trong bài viết này, mình sẽ giới thiệu với các bạn những thông tin cơ bản về Debezium để các bạn có thể sử dụng nó trong các ứng dụng của mình các bạn nhé!
Điều đầu tiên mình cần nói với các bạn là về các cách sử dụng Debezium.
Các cách sử dụng Debezium
Hiện tại chúng ta có thể sử dụng Debezium theo 3 cách khác nhau:
Cách đầu tiên là chúng ta sẽ sử dụng Debezium với Apache Kafka Connect:
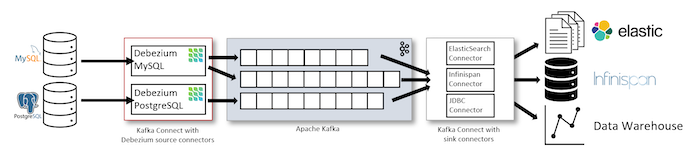
Chúng ta sẽ cài đặt Debezium Source Connector cho database mà chúng ta muốn capture vào Apache Kafka Connect. Connector này sẽ có nhiệm vụ capture và publish các thông tin data change trong database vào Apache Kafka Topic. Nếu muốn đẩy các data change trong Apache Kafka Topic này vào các hệ thống khác, các bạn có thể sử dụng các Sink Connector của Apache Kafka Connect.
Các database hiện tại Debezium support là:
- MongoDB
- MySQL
- PostgreSQL
- SQL Server
- Oracle
- Db2
- Cassandra
- Vitess
- Spanner
- JDBC
- Informix
Cách thứ hai là chúng ta sẽ sử dụng Debezium Server.
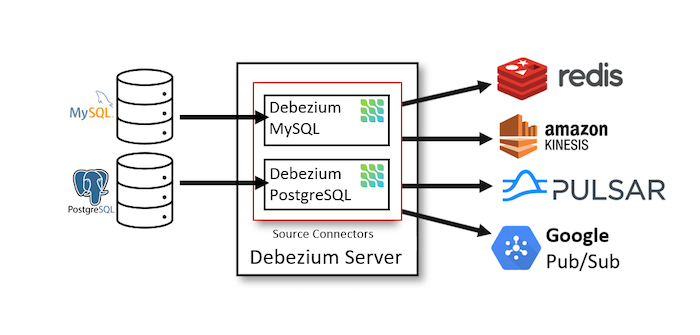
Debezium Server mặc định support các Source Connectors để connect tới các database để capture data change. Sau khi capture được data change, Debezium sẽ public những data này vào các message broker hoặc event broker sử dụng các Sink Connectors.
Danh sách các database mà Debezium hiện tại support thì mình đã liệt kê ở trên. Còn danh sách event broker hay message broker tương ứng với các Sink Connectors được Debezium hỗ trợ như sau các bạn nhé:
- Amazon Kinesis
- Google Cloud Pub/Sub
- Pub/Sub Lite
- HTTP Client
- Apache Pulsar
- Azure Event Hubs
- Redis (Stream)
- NATS Streaming
- NATS JetStream
- Apache Kafka
- Pravega
- Infinispan
- Apache RocketMQ
- RabbitMQ Stream
- RabbitMQ Native Stream
Các bạn cũng có thể hiện thực một Sink Connector mới để publish các data change được capture bởi Debezium tới các destination khác các bạn nhé!
Cách thứ 3 thì chúng ta có thể sử dụng Debezium Engine.
Với cách này thì chúng ta sẽ sử dụng Debezium dưới dạng một library trong các application. Chúng ta không cần sử dụng Apache Kafka hay start Debezium Server mà chỉ cần sử dụng code trong các application để consume các change data trong database mà chúng ta muốn.
Bây giờ, mình sẽ sử dụng Debezium Server để làm ví dụ cho các bạn dễ hình dung các bạn nhé!
Capture data change với Debezium Server
Các bạn có thể download latest version của Debezium Server ở đây. Phiên bản release mới nhất tại thời điểm mình viết bài này là 3.0.0.Final.
Trước khi setup để start Debezium lên, chúng ta cần setup cho database mà chúng ta cần capture data change và cả destination mà chúng ta muốn publish những data này trước các bạn nhé!
Mình sẽ sử dụng PostgreSQL database để capture data change, và Apache Kafka để nhận những data change này, để làm ví dụ nha các bạn!
Phần cấu hình PostgreSQL để Debezium có thể capture những data change, các bạn hãy tham khảo bài viết này nhé! Mình có liệt kê chi tiết các bước để cấu hình và mình sẽ sử dụng logical decoding output plugin có sẵn của PostgreSQL là pgoutput các bạn nhé!
Sau khi download tập tin cài đặt của Debezium về, các bạn hãy giải nén nó ra:
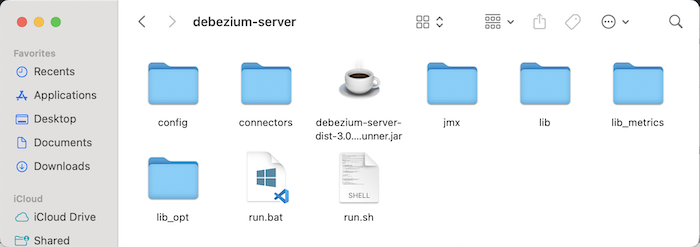
Trong thư mục config của Debezium Server, các bạn sẽ thấy có các tập tin properties ví dụ mà chúng ta có thể sử dụng để cấu hình cho các connector với Debezium.
Để làm ví dụ cho bài viết này, mình sẽ duplicate tập tin application.properties.example lên rồi rename nó thành application.properties. Mình sẽ cấu hình một connector tới PostgreSQL database với Debezium Server sử dụng tập tin application.properties này.
Có 2 phần mà chúng ta cần cầu hình cho một connector đó là phần Source và phần Sink. Các khái niệm Source và Sink của Debezium nó cũng giống như trong Apache Kafka Connect đó các bạn! Source là system emit data còn Sink thì sẽ là system nhận các data này.
Source trong ví dụ của mình là PostgreSQL database, các bạn có thể cấu hình thông tin về Source với PostgreSQL database như mình, như sau:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
debezium.source.connector.class=io.debezium.connector.postgresql.PostgresConnector debezium.source.database.hostname=localhost debezium.source.database.port=5432 debezium.source.database.user=postgres debezium.source.database.password=123456 debezium.source.database.dbname=debezium_example debezium.source.topic.prefix=debezium_example debezium.source.offset.storage.file.filename=data/offsets.dat debezium.source.offset.flush.interval.ms=0 debezium.source.schema.history.internal=io.debezium.storage.file.history.FileSchemaHistory debezium.source.schema.history.internal.file.filename=data/schema-history.dat debezium.source.plugin.name=pgoutput |
Ngoài thông tin về database connection tới PostgreSQL database, chúng ta còn cần khai báo connector class của Debezium sẽ handle cho PostgreSQL database là io.debezium.connector.postgresql.PostgresConnector.
Property debezium.source.topic.prefix được sử dụng để định nghĩa prefix cho tất cả các Apache Kafka topic sẽ nhận data changes từ connector này. Nếu các bạn định nghĩa nhiều connector thì giá trị của property này phải là duy nhất cho mỗi connector.
Có 2 cấu hình cũng quan trọng mà các bạn có thể thấy ở trên là về offset và schema history.
- Offset sẽ chứa thông tin về những record mà Debezium đã process, nếu có những data change mới thì Debezium sẽ không process những record cũ nữa. Cho non-Kafka deployment, chúng ta có thể lưu trữ thông tin offset này sử dụng một tập tin hoặc memory hoặc sử dụng 1 database table hoặc một Redis server. Mặc định thì Debezium sẽ sử dụng file như mình khai báo thông tin filename ở trên. Nếu sử dụng file như mình như trên, các bạn cần đảm bảo thư mục data tồn tại nhé, Debezium sẽ tự động tạo các tập tin cần thiết.
- Schema history sẽ lưu trữ thông tin về database schema theo thời gian. Cho non-Kafka deployment, các bạn có thể sử dụng một tập tin hoặc memory hoặc một Redis server hoặc một RocketMQ server. Mặc định thì schema history này sẽ sử dụng Apache Kafka để lưu trữ các bạn nhé! Cho non-Kafka deployment, ví dụ như sử dụng một tập tin như mình cấu hình ở trên, các bạn cần phải khai thêm tên class sẽ handle phần schema history này. Cho ví dụ của mình thì mình đã khai báo thêm class io.debezium.storage.file.history.FileSchemaHistory cho property debezium.source.schema.history.internal.
Mặc định thì Debezium sẽ sử dụng tìm kiếm tập tin được output bởi logical decoding output plugin decoderbufs của PostgreSQL, do đó các bạn cần phải cấu hình thêm property debezium.source.plugin.name với giá trị là pgoutput để Debezium sử dụng output file của plugin pgoutput các bạn nhé! Mình sẽ sử dụng plugin pgoutput nên mình đã khai báo như trên.
Cho database debezium_example, mình định nghĩa một table như sau:
|
1 2 3 4 |
CREATE TABLE student ( id bigint NOT NULL PRIMARY KEY, name VARCHAR (100) ) |
Cho phần Sink, mình sẽ sử dụng Apache Kafka. Mình sẽ khai báo như sau:
|
1 2 3 4 |
debezium.sink.type=kafka debezium.sink.kafka.producer.bootstrap.servers=127.0.0.1:9092 debezium.sink.kafka.producer.key.serializer=org.apache.kafka.common.serialization.StringSerializer debezium.sink.kafka.producer.value.serializer=org.apache.kafka.common.serialization.StringSerializer |
Type của Sink sẽ có giá trị là kafka và ngoài thông tin về Kafka server, các bạn còn cần phải cấu hình thêm các property kafka.producer.key.serializer và kafka.producer.value.serializer của Apache Kafka các bạn nhé!
Toàn bộ nội dung của tập tin application.properties của mình như sau:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
debezium.source.connector.class=io.debezium.connector.postgresql.PostgresConnector debezium.source.database.hostname=localhost debezium.source.database.port=5432 debezium.source.database.user=postgres debezium.source.database.password=123456 debezium.source.database.dbname=debezium_example debezium.source.topic.prefix=debezium_example debezium.source.offset.storage.file.filename=data/offsets.dat debezium.source.offset.flush.interval.ms=0 debezium.source.schema.history.internal=io.debezium.storage.file.history.FileSchemaHistory debezium.source.schema.history.internal.file.filename=data/schema-history.dat debezium.source.plugin.name=pgoutput debezium.sink.type=kafka debezium.sink.kafka.producer.bootstrap.servers=127.0.0.1:9092 debezium.sink.kafka.producer.key.serializer=org.apache.kafka.common.serialization.StringSerializer debezium.sink.kafka.producer.value.serializer=org.apache.kafka.common.serialization.StringSerializer |
Bây giờ thì chúng ta có thể start Debezium server lên rồi.
Các bạn hãy mở Terminal hoặc Console lên, trong thư mục cài đặt của Debezium, hãy chạy command sau các bạn nhé:
|
1 |
./run.sh |
trên Linux, macOS hoặc:
|
1 |
./run.bat |
trên Windows.
Các bạn sẽ thấy kết quả như mình, như sau:
Kiểm tra các topic trong Apache Kafka server, các bạn cũng sẽ thấy một topic mới được tạo ra, ví dụ của mình như sau:
Bây giờ, nếu bạn thử thêm mới một record vào table student của PostgreSQL, các bạn sẽ thấy một topic mới được tạo trong Apache Kafka, ví dụ như sau:
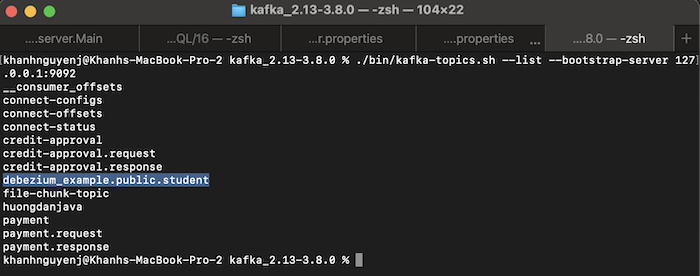
Trong ví dụ của mình, topic trong Apache Kafka đã được tạo bởi Debezium sử dụng naming convention như sau:
- Đầu tiên là giá trị của property topic.prefix mà chúng ta đã cấu hình trong tập tin application.properties
- Tiếp theo là tên của schema
- Và cuối cùng là tên table mà data sẽ được capture bởi Debezium
Kiểm tra topic này, các bạn cũng sẽ thấy một message được public với nội dung như sau:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 |
{ "schema": { "type": "struct", "fields": [ { "type": "struct", "fields": [ { "type": "int64", "optional": false, "field": "id" }, { "type": "string", "optional": true, "field": "name" } ], "optional": true, "name": "debezium_example.public.student.Value", "field": "before" }, { "type": "struct", "fields": [ { "type": "int64", "optional": false, "field": "id" }, { "type": "string", "optional": true, "field": "name" } ], "optional": true, "name": "debezium_example.public.student.Value", "field": "after" }, { "type": "struct", "fields": [ { "type": "string", "optional": false, "field": "version" }, { "type": "string", "optional": false, "field": "connector" }, { "type": "string", "optional": false, "field": "name" }, { "type": "int64", "optional": false, "field": "ts_ms" }, { "type": "string", "optional": true, "name": "io.debezium.data.Enum", "version": 1, "parameters": { "allowed": "true,last,false,incremental" }, "default": "false", "field": "snapshot" }, { "type": "string", "optional": false, "field": "db" }, { "type": "string", "optional": true, "field": "sequence" }, { "type": "int64", "optional": true, "field": "ts_us" }, { "type": "int64", "optional": true, "field": "ts_ns" }, { "type": "string", "optional": false, "field": "schema" }, { "type": "string", "optional": false, "field": "table" }, { "type": "int64", "optional": true, "field": "txId" }, { "type": "int64", "optional": true, "field": "lsn" }, { "type": "int64", "optional": true, "field": "xmin" } ], "optional": false, "name": "io.debezium.connector.postgresql.Source", "field": "source" }, { "type": "struct", "fields": [ { "type": "string", "optional": false, "field": "id" }, { "type": "int64", "optional": false, "field": "total_order" }, { "type": "int64", "optional": false, "field": "data_collection_order" } ], "optional": true, "name": "event.block", "version": 1, "field": "transaction" }, { "type": "string", "optional": false, "field": "op" }, { "type": "int64", "optional": true, "field": "ts_ms" }, { "type": "int64", "optional": true, "field": "ts_us" }, { "type": "int64", "optional": true, "field": "ts_ns" } ], "optional": false, "name": "debezium_example.public.student.Envelope", "version": 2 }, "payload": { "before": null, "after": { "id": 2, "name": "Khanh" }, "source": { "version": "3.0.0.Final", "connector": "postgresql", "name": "debezium_example", "ts_ms": 1729780744026, "snapshot": "false", "db": "debezium_example", "sequence": "[null,\"64154288\"]", "ts_us": 1729780744026695, "ts_ns": 1729780744026695000, "schema": "public", "table": "student", "txId": 833, "lsn": 64154288, "xmin": null }, "transaction": null, "op": "c", "ts_ms": 1729780744093, "ts_us": 1729780744093672, "ts_ns": 1729780744093672000 } } |
Message trên chia thành 2 phần: schema và payload. Phần schema định nghĩa schema cho phần payload. Như các bạn thấy, trong phần payload của message trên, vì chúng ta thêm mới record nên giá trị của attribute op, viết tắt của từ operation, sẽ là c, viết tắt của từ create. Thuộc tính before sẽ là null, còn thuộc tính after thì là thông tin của record mà mình mới thêm vào.
Ngoài ra, còn rất nhiều thông tin khác về database, schema, table mà các bạn có thể thấy ở trên.
Khi chúng ta update, thì các bạn sẽ thấy message mới có nội dung tương tự như sau:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
{ "schema": { ... }, "payload": { "before": null, "after": { "id": 3, "name": "Khanh Nguyen" }, "source": { "version": "3.0.0.Final", "connector": "postgresql", "name": "debezium_example", "ts_ms": 1730156708096, "snapshot": "false", "db": "debezium_example", "sequence": "[\"64157160\",\"64157448\"]", "ts_us": 1730156708096090, "ts_ns": 1730156708096090000, "schema": "public", "table": "student", "txId": 837, "lsn": 64157448, "xmin": null }, "transaction": null, "op": "u", "ts_ms": 1730156708181, "ts_us": 1730156708181839, "ts_ns": 1730156708181839000 } } |
Với message này, thuộc tính op sẽ có giá trị là u, viết tắt của từ update.
Các bạn có thể để ý thấy là thuộc tính before với mục đích lưu trữ giá trị trước đó của record mà chúng ta vừa update, giá trị cũng là null. Nguyên nhân là bởi vì cấu hình REPLICA IDENTITY (một cấu hình liên quan đến việc, bao nhiêu thông tin sẽ available trong trường hợp một record được UPDATE hoặc DELETE trong database) ở level table của PostgreSQL database, mặc định sẽ chỉ lưu lại giá trị trước đó cho các primary key columns. Nếu primary key columns có change giá trị thì giá trị trước đó của column này sẽ được gán cho thuộc tính before. Các bạn có thể xem thêm ở đây để hiểu thêm về các cấu hình của REPLICA IDENTITY của PostgreSQL database các bạn nhé!
Các bạn có thể thay đổi cấu hình mặc định này để record hết tất cả các giá trị trước đó của tất cả các column bằng cách chạy câu lệnh SQL sau cho table mà chúng ta muốn capture data change:
|
1 |
ALTER TABLE <table_name> REPLICA IDENTITY FULL; |
Ví dụ của mình như sau:
|
1 |
ALTER TABLE public.student REPLICA IDENTITY FULL; |
Bây giờ nếu mình thay đổi giá trị của một record trong table student, mình sẽ thấy một message như sau:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
{ "schema": { ... }, "payload": { "before": { "id": 3, "name": "Khanh Nguyen" }, "after": { "id": 3, "name": "Khanh Nguyen Huu" }, "source": { "version": "3.0.0.Final", "connector": "postgresql", "name": "debezium_example", "ts_ms": 1730159058629, "snapshot": "false", "db": "debezium_example", "sequence": "[\"64158040\",\"64169032\"]", "ts_us": 1730159058629592, "ts_ns": 1730159058629592000, "schema": "public", "table": "student", "txId": 839, "lsn": 64169032, "xmin": null }, "transaction": null, "op": "u", "ts_ms": 1730159059030, "ts_us": 1730159059030450, "ts_ns": 1730159059030450000 } } |
Như các bạn thấy, giá trị trước đó của record cũng được gán cho thuộc tính before.
Như vậy là chúng ta đã hiện thực thành công data change capture cho PostgreSQL database rồi đó các bạn!
Các bạn có thể xem thêm video ở đây
và

