
Trong bài viết trước, mình đã giới thiệu với các bạn về Spring for Apache Kafka cùng với Apache Kafka Streams. Mình cũng đã hướng dẫn cho các bạn cách sử dụng class KStream để consume và áp dụng một số operation với các stream message. Ngoài class KStream này thì trong Spring for Apache Kafka Streams thì chúng ta còn có class KTable làm nhiệm vụ nắm giữ latest value của một key nào đó. Các bạn có thể public nhiều message với cùng 1 key, KTable giúp chúng ta có thể lấy giá trị mới nhất của key đó, đó các bạn! Cụ thể như thế nào? Chúng ta hãy cùng nhau tìm hiểu trong video này các bạn nhé!
Mình sẽ sử dụng project ví dụ của bài viết trước để làm ví dụ cho bài viết này.
Class KTable hoạt động giống như một table có 2 column là key và value vậy đó các bạn! Ví dụ mình public 1 số message theo thứ tự như sau:
| Key | Value | |
|---|---|---|
| 1 | 100 | A |
| 2 | 200 | B |
| 3 | 100 | C |
thì KTable sẽ nắm giữ giá trị mới nhất của các key như sau:
| Key | Value |
|---|---|
| 100 | C |
| 200 | B |
Trong ví dụ trên thì message với key 100 được publish 2 lần, KTable sẽ record giá trị mới nhất của 100 là C đó các bạn!
Các bạn có thể consume các message và sử dụng KTable để record lastest value của các message key bằng cách khai báo 1 bean của class KTable như sau:
|
1 2 3 4 5 6 7 8 |
@Bean public KTable<String, String> customers(StreamsBuilder builder) { KTable<String, String> customers = builder.table("customers"); customers.toStream().foreach((key, value) -> System.out.println(key + " -> " + value)); return customers; } |
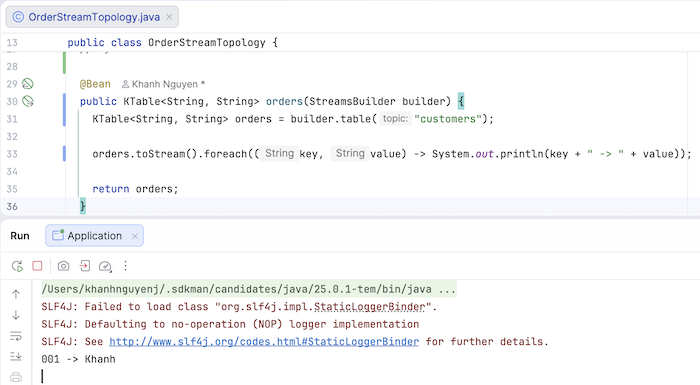
Chúng ta sử dụng phương thức table() của class StreamsBuilder cùng với tên topic để khởi tạo đối tượng của class KTable. Với ví dụ trên, mỗi khi một message mới được publish vào topic customers:
 một message với key và value sẽ được in ra console như sau:
một message với key và value sẽ được in ra console như sau:
Các bạn có thể count số lượng message có cùng key được publish vào một topic như sau:
|
1 2 3 4 5 6 7 8 |
@Bean public KTable<Object, Long> customers(StreamsBuilder builder) { KTable<Object, Long> customers = builder.stream("customers").groupByKey().count(); customers.toStream().foreach((key, value) -> System.out.println(key + " : " + value)); return customers; } |
Lúc này chạy lại ví dụ, các bạn sẽ thấy trong Apache Kafka, một Kafka changelog topic mới được tạo:
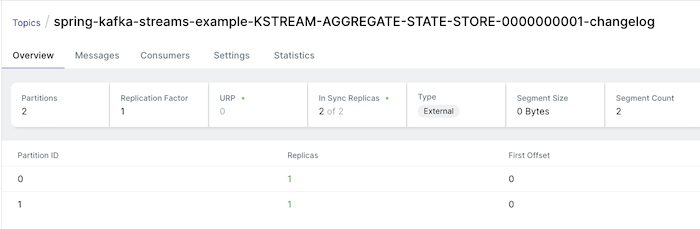
Kafka changelog topic này được sử dụng để có thể rebuild lại state của các message key trong trường hợp có vấn đề về ổ đĩa lưu trữ đó các bạn!
Trong console của ứng dụng, các bạn cũng thấy một số warning về thư viện RocksDB:
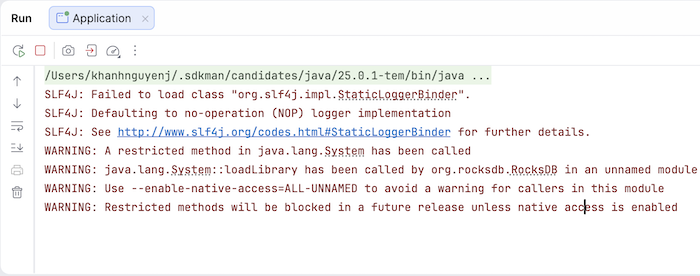
Bản chất là Apache Kafka Streams sử dụng RocksDB để lưu giữ trạng thái của dữ liệu đó các bạn, giúp chúng ta có thể query các thông tin mà chúng ta muốn. Trong trường hợp RocksDB có vấn đề, Apache Kafka Streams sẽ rebuild lại state dựa vào Kafka changelog topic mà mình đã nói ở trên.
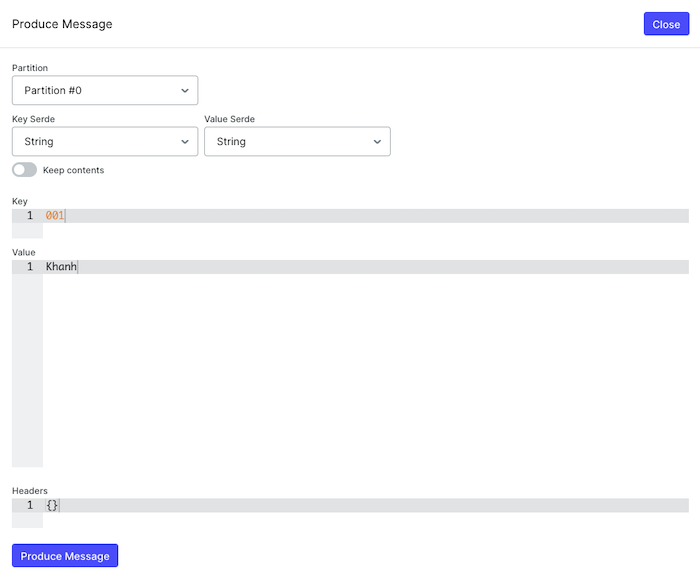
Bây giờ, nếu mình publish thêm một số message theo thứ tự với:
- key là 001, value là Khanh
- key là 002, value là Huong Dan Java
- key là 001, value là Khanh Nguyen
thì các bạn sẽ thấy kết quả như sau:
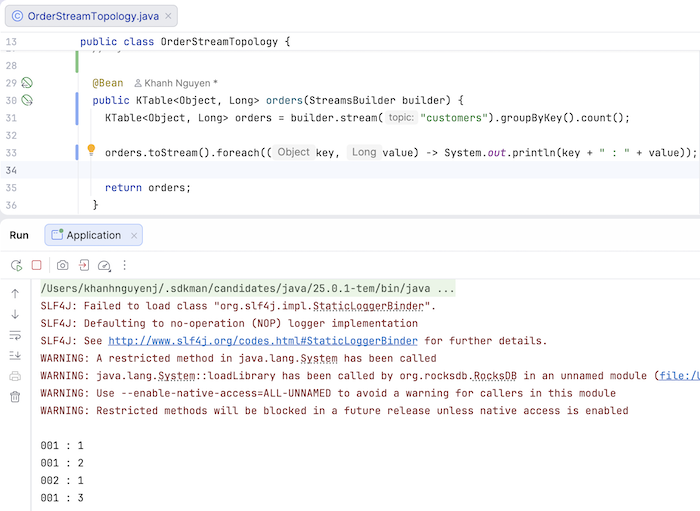
Cộng với message mà mình đã publish trước đó thì tổng số message cho key 001 là 3 và 002 là 1 đó các bạn!
Để có thể thấy việc KTable nắm giữ latest value của một key, mình sẽ sử dụng join() để join các message của 2 topic là customers và ordersnhư sau:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
@Bean public KStream<String, String> orders(StreamsBuilder builder) { KTable<String, String> customers = builder.table("customers"); KStream<String, String> orders = builder.stream("orders"); orders .join( customers, (ValueJoiner<String, String, Object>) (orderName, customerName) -> { System.out.println( "Joining order: " + orderName + " with customer: " + customerName); return String.format("%s ordered %s", customerName, orderName); }, Joined.with(Serdes.String(), Serdes.String(), Serdes.String())) .to("enriched-orders"); return orders; } |
Chúng ta sẽ sử dụng KTable để lấy latest value of một customer và KStream để consume và thực hiện operation join() đối với thông tin order. Tương tự như trong table của database, chúng ta sẽ sử dụng key của các topic customers và orders để join. Sau khi join xong, kết quả sẽ được publish vào topic enriched-orders đó các bạn!
Chạy ứng dụng này lên, các bạn cũng sẽ thấy có một topic liên quan đến customers cũng sẽ được tạo như sau:
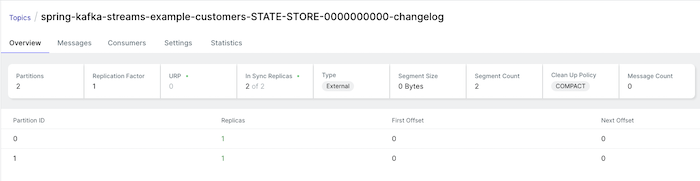
Nếu bây giờ các bạn chạy lại ứng dụng rồi publish một message vào topic orders, ví dụ như key là ‘001’ và value là ‘Table’ thì các bạn sẽ thấy kết quả như sau:
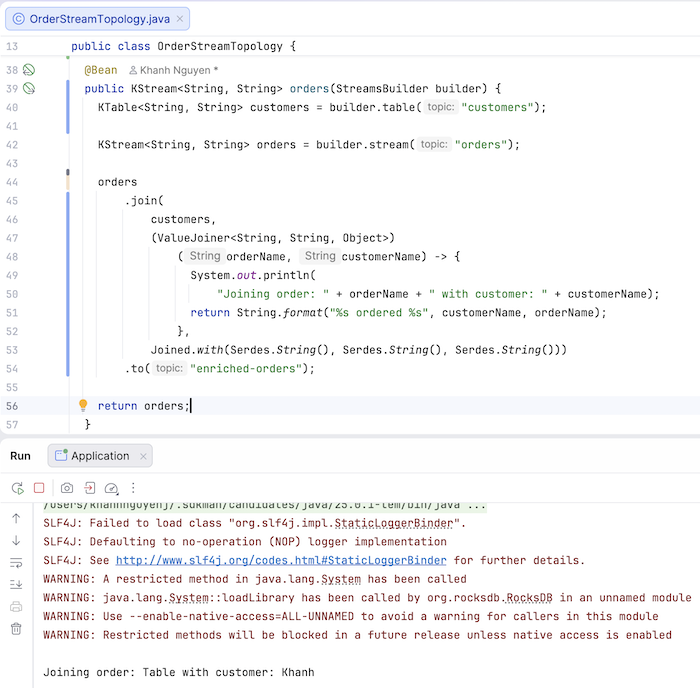
Một message cũng được publish vào topic enriched-orders như sau:

Nếu bây giờ các bạn update thông tin của customer ‘001’ thành ‘ Khanh Nguyen’ bằng cách gửi một message vào topic customers với key là ‘001’, value là ‘Khanh Nguyen’. Sau đó thì publish một message khác vào topic orders thì các bạn sẽ thấy latest value của customer ‘001’ sẽ được sử dụng.
Kết quả như sau:
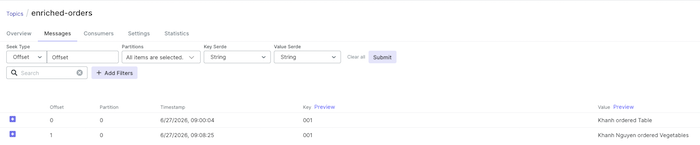
Các bạn có thể xoá 1 key trong KTable bằng cách publish một message cùng key với giá trị null các bạn nhé! Trong ví dụ của mình thì sau khi đã xoá key ‘001’ trong KTable và publish một message với topic orders, các bạn sẽ không thấy một message nào được publish vào topic enriched-orders nữa!
Các bạn có thể xem thêm video ở đây
